Overview
- My research interests lie at the intersection of machine learning, information and data sciences, and causal reasoning. My research agenda focuses on responsible artificial intelligence with emphasis on learning from biased, imperfect and decentralized data. This includes issues of fairness, explainability, privacy, security and ethical considerations. Ongoing and planned (next 5-year) research topics include: (i) Fair and explainable machine learning (ML) algorithms (ongoing); (ii) Fair, private, personalized and robust federated learning (FL), as well as \\ its application to health informatics and social sciences (ongoing); (iii) Causal inference and discovery in latent-variable and complex-data models (ongoing); (iv) Causal fairness and causal representation learning for interpretability/explainability (planned); (v) Private and secure ML: Differential privacy; Secure communication & storage of data and models (planned)
- I use tools from statistical learning, optimization, information theory, causal inference and computation complexity. On the application side, I have a wide range of interests from data science, wireless communication, edge/distributed computing, autonomous driving, to social \& policy sciences, humanities & philosophy, and health informatics.
- My doctoral and masters studies focused on problems in information theory & wireless communications. My PhD thesis –titled “Information-theoretic security against more capable adversaries”– investigated fundamental limits, algorithmic foundations and provable guarantees for physical-layer security mechanisms in presence of strong adversaries (e.g., adversaries with more physical resources or adversaries capable of performing strategic eavesdropping) and for various network topologies and communication protocols.
Ongoing Projects:
-
1. Algorithmic fairness in machine learning (ML)
- Despite the growing success of ML systems in accomplishing complex tasks, their increasing use in making or aiding consequential decisions that affect people’s lives (e.g., healthcare, university admission, predictive policing) raises concerns about potential discriminatory practices. Unfair outcomes in ML systems result from (i) historical discriminatory biases in the training data and/or (ii) unbalanced demographics leading to biased error-minimizing algorithms (higher accuracy for the “majority” group maintains high overall accuracy). Understanding and quantifying such biases is a challenging and important problem, leading to constructive insights and methodologies for bias/discrimination mitigation in data-driven AI systems, and raises the need for policy changes and infrastructural development. The challenge here lies in the complex structures of correlation/causation among non-sensitive covariates, sensitive (legally protected) covariates, labels or target variables, and prediction outcomes, as well as the high-dimensionality of today’s data.
1.1. Information-theoretic framework for fairness-aware supervised learning [Khodadian, Nafea, et al., 2021]
- Most previous work in ML fairness formulates the problem from the viewpoint of the “learning algorithm” by enforcing statistical or counterfactual fairness constraint(s) on its outcomes while maintaining its performance accuracy. As the “unfairness” problem originates from biased/unbalanced data, merely adding constraints to the learning/prediction task does not provide a holistic view of its fundamental limitations. This project looks at the problem through different lens, particularly, we analyze the inherent tradeoff in the data via quantifying the marginal impacts of individuals’ covariates on discrimination and accuracy of any downstream supervised ML task, while taking into account the correlations among system variables. We advocate for using information-theoretic metrics along with tools from game theory and causal reasoning to account for the desired correlations and causal effects in constructing measures for marginal accuracy and discrimination impacts of covariates. We use the constructed measures to guide a simple feature-selection algorithm which minimizes discrimination bias while maintaining reasonable accuracy. We validate our algorithmic framework on synthetic and real data.
-
1.2. Extension to various ML tasks & bias mitigation methods (Ongoing work)
- We are investigating the effectiveness of our framework in Section 1.1. when combined with various existing methods for bias mitigation such as data resampling and representation learning. Further, our measures for marginal accuracy and discriminatory impacts of covariates are based on a partial decomposition of mutual information into shared, unique, and synergistic components, which can be computationally challenging to estimate, especially for high-dimensional data. We are investigating more computationally efficient approximations (upper/lower bounds) of the proposed measures for scalable implementation.
- Despite the growing success of ML systems in accomplishing complex tasks, their increasing use in making or aiding consequential decisions that affect people’s lives (e.g., healthcare, university admission, predictive policing) raises concerns about potential discriminatory practices. Unfair outcomes in ML systems result from (i) historical discriminatory biases in the training data and/or (ii) unbalanced demographics leading to biased error-minimizing algorithms (higher accuracy for the “majority” group maintains high overall accuracy). Understanding and quantifying such biases is a challenging and important problem, leading to constructive insights and methodologies for bias/discrimination mitigation in data-driven AI systems, and raises the need for policy changes and infrastructural development. The challenge here lies in the complex structures of correlation/causation among non-sensitive covariates, sensitive (legally protected) covariates, labels or target variables, and prediction outcomes, as well as the high-dimensionality of today’s data.
-
2. Towards fair and trust-worthy federated learning
-
- Federated learning (FL) is a paradigm for collaborative and computation-efficient training of ML models for better generalization, while promoting higher privacy guarantees via maintaining local data local. Instead, clients train local model updates and only these updates are shared and aggregated globally: A client could be a mobile device in a wireless network (cross-device FL) or a branch in hospital or bank system (cross-silo FL). Initial efforts focused on learning a single global model with good average performance guarantees across clients. However, due to statistical heterogeneity of clients’ data, the global model may be arbitrarily bad for some clients. Researchers proposed several frameworks for personalizing the learnt model(s), while continue benefiting from improved generalization due to global training. These include (i) training a single global model with better worst-case performance, or (ii) training distinct personalized models for different clients (or clusters/groups of clients.) This project aims at studying group-fairness and privacy-preserving mechanisms in various PFL settings.
2.1 Proportionally fair clustered federated learning (CFL) [Nafea, et al., 2022]
- CFL is a commonly used frameworks for learning personalized models in FL: Clients are partitioned into disjoint clusters based on their data distribution and a distinct model is learnt for each cluster, yet ground-truth cluster assignments are unknown. This work inspects CFL under the “disparate impact doctrine” which requires that protected groups, those of certain race or gender, have representations in every cluster that are approximately equal to their global counterparts, see Figure 1. We propose an “alternate minimization algorithm” which alternates between learning cluster assignments and training distinct models for different clusters. Our algorithm balances between the learning performance and proportional fairness through cluster assignments as randomized functions of the learning losses. The theoretical trade-off induced by the algorithm, between accuracy of cluster estimation versus proportional fairness, is characterized. The proposed algorithm is examined on the “Adult” dataset to evaluate its performance.
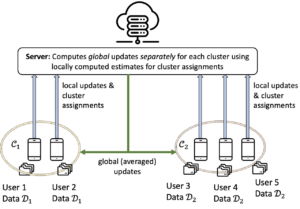
Figure 1: CFL example: Server aims to train models for job advertisement (to predict whether a user will click on an ad). A different ad is shown to clusters C1 and C2; for example, a STEM job is advertised to cluster C1 and a non-STEM job is advertised to cluster C2, based on users browsing history (different data distributions). Here, we want to ensure, for example, that ads for STEM jobs are not shown overwhelmingly to male users. 2.2. Personalized cross-silo FL under group-fairness constraints (Ongoing work)
-
Group fairness in ML ensures that individuals from minority groups are not experiencing worse “learning performance” than others. Various bias mitigation methods were proposed to exactly (or approximately) satisfy group fairness while maintaining reasonable learning accuracy. A rather direct approach to extend group fairness guarantees to federated settings is to apply conventional bias mitigation methods locally to clients during their training phase; and subsequently aggregate the resulting “bias-free” local models. However, due to data heterogeneity across clients, which is often the case in FL, simple local debasing methods may result in faulty estimates of the fairness guarantees. In this project, we investigate various approaches for addressing “group fairness” in data-heterogenous cross-silo FL, including adversarial training, representation learning, and regularization. We are also studying the tensions & compatibilities between personalization, privacy, and group fairness objectives in FL.
-
- Federated learning (FL) is a paradigm for collaborative and computation-efficient training of ML models for better generalization, while promoting higher privacy guarantees via maintaining local data local. Instead, clients train local model updates and only these updates are shared and aggregated globally: A client could be a mobile device in a wireless network (cross-device FL) or a branch in hospital or bank system (cross-silo FL). Initial efforts focused on learning a single global model with good average performance guarantees across clients. However, due to statistical heterogeneity of clients’ data, the global model may be arbitrarily bad for some clients. Researchers proposed several frameworks for personalizing the learnt model(s), while continue benefiting from improved generalization due to global training. These include (i) training a single global model with better worst-case performance, or (ii) training distinct personalized models for different clients (or clusters/groups of clients.) This project aims at studying group-fairness and privacy-preserving mechanisms in various PFL settings.
-
-
-
-
2.3. Personalized & fair cross-silo FL for realistic healthcare settings (Ongoing work)
-
-
-
-
-
- In this project, we are building on an existing benchmark for cross-silo FL for “medical diagnostic” applications including image (X-rays, CT scans, Dermoscopy images), tabular, and multi-modal datasets [15]. Our focus is on the aspects of personalization, privacy, and group fairness.
-
-
-
-
3. Causal discovery in linear structural causal models with latent variables
-
A fundamental task in various disciplines of science, e.g., biology, economics, artificial intelligence, is to find underlying causal relations and make use of them. Causal relations can be deduced if interventions are properly applied, as in randomized controlled trials, or RCTs. However, interventions can be unethical, difficult, or impossible to conduct, leading to the need to discover causal relations by analyzing statistical properties of purely observational data; known as causal discovery. The majority of existing work consider models where (i) all variables are observed, (ii) observed variables are accurately measured without error, and (iii) variables are not allowed to deterministically depend on one another. In some practical applications, these assumptions lead to significant oversimplification, hence existing algorithms fail to recover the correct causal structures. The following work tackles these challenges in the context of linear structural causal models (SCMs) which are pervasive in causal discovery.
-
3.1 Linear structural causal models with deterministic relations [Yang, Ghassami, Nafea, et al., 2022]
-
A common assumption in SCMs is that every observed/unobserved variable is associated with at least one independent exogenous source (idiosyncratic factor) with non-zero variance. This is to avoid deterministic dependencies among variables. Nevertheless, deterministic relations appear in multiple real-world scenarios, e.g, social \& recommendation networks, political campaigns and epidemiology. For instance, in a setting of spread of news/opinios, a large group of individuals may have their news/opinions exclusively from a limited set of sources (see Fig. \ref{fig1-ground-truth}). Only a handful of previous works discussed the case of deterministic relations; in very limited settings and only under causal sufficiency (no unobserved confounders). The challenge with deterministic relations is two-fold. First, deterministic relations limit the use of “d-separation”, a key concept needed for causal discovery in SCMs. Second, defining deterministic relations in presence of latent confounders is intricate, as it requires relaxing the distinction between unobserved confounders and unobserved exogenous sources. This work is the first to provide a general formulation for linear SCMs with deterministic relations and study deterministic relations in presence of latent variables. We derive the exact conditions for unique identifiability of the causal structure from observational data, and propose an algorithm for recovering causal structures when possible. We show empirically that these conditions are more likely to be satisfied in sparser causal diagrams. Fig. 2 highlights our contribution to existing works in causal discovery.
-
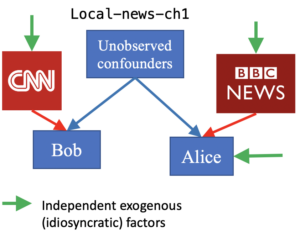
2a. Ground-truth: Alice/Bob updates her/his twitter-feed based on (BBC, local-news-ch1, and an ideosyncratic factor)/(CNN news & local-news-ch1). Here, Bob’s feed is deterministic in the observed variable (CNN) and the unobserved confounder (local-news-ch1). -
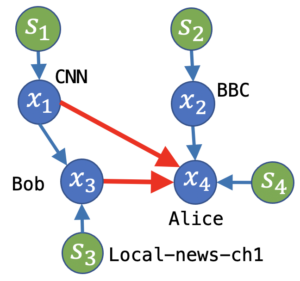
2b. Existing methods fail to model deterministic relations in presence of unobserved confounders leading to incorrect recovery: The recovered causal structure includes links from CNN & Bob to Alice to substitute for incorrectly modeling local-news-ch1 s3 as Bob’s idiosyncratic factor. -
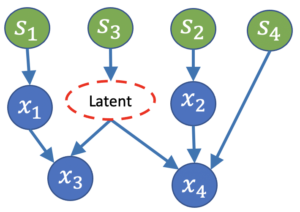
2c. Our model: Every observed variable is a linear function of its observed parents and {\it{a set of independent sources}} which models both unobserved confounders and idiosyncratic factors. Based on this model, our algorithm successfully recovers the correct causal structure from observations.
-
-
-
-
-
-
-
3.2 Linear latent-variable models subject to measurement error [Yang, Ghassami, Nafea, et al., 2022]
-
-
Presence of measurement errors is common in many applications including neuroscience, social \& recommendation networks, and survey studies. Only a few works in SCMs considered modeling errors in measuring observed variables. In this work, we demonstrate a surprising connection between linear SCMs with measurement errors (SCM-ME) and linear SCMs with unobserved confounders (or roots), SCM-UR. Specifically, we show there is a mapping between the underlying models to be inferred in these two problems; see Fig. \ref{fig2-mapping}. Consequently, any identifiability result for one model translates to an identifiability result for the other. Indeed, SCM-ME is much less studied than SCM-UR, hence our result fills a significant gap in the literature. We also characterize the extent of identifiability for the two models under mild faithfulness assumptions. Based on our theoretical results, we propose causal structure learning methods for both models which can recover the corresponding graphs up to their respective levels of identifiability.
-
-
-
Completed Projects:
-
-
1. Information-theoretic security guarantees against more capable adversaries
- Earlier approaches to information-theoretic security assume an adversary that is weaker than legitimate terminals and is a passive entity performing no designed attacks. This research aimed at addressing these challenges by introducing stronger adversaries in existing models, and new adversarial models in emerging communication systems.
-
-
-
-
1.1. Adversarial resource advantage
An adversary with resource advantage to deploy more antennas than legitimate terminals can deteriorate secure communication. A viable solution is to enlist a helper terminal to help diminish the adversary’s reception. The helper terminal can be another legitimate terminal in the network (e.g., base station), a relay, or even a reconfigurable reflecting surface. The following works tackle this problem.
-
- a. Multi-antenna wiretap channel with multi-antenna helper [Nafea,Yener,2017]. This work characterizes the scaling behavior of the secure transmission rate (as a function of transmit power) for the multiantenna wiretap channel with a multi-antenna helper. On the algorithmic side, we proposed a variety of beam-forming, interference alignment, and encoding schemes to coordinate the transmitted and received signals at different terminals. Our results show that the augmented helper (user cooperation) countervails the adversarial resource advantage. This work served as an initial step towards quantifying the benefits of user cooperation for security in multiantenna communication networks (see citations at https://scholar.google.com/scholar oi=bibs&hl=en&cites=15634518658480682008)
- b. Multi-antenna wiretap channel with an intelligent reconfigurable surface (IRS) [Nafea, Yener, 2021]. Intelligent reconfigurable surfaces (IRS) is a candidate technology for next generation of wireless (6G), for improving reliability and range extension owing to their low cost& complexity and suitability for high-frequency schemes. IRS terminals can effectively operate as relaying nodes for transmitted signals while saving the energy required for RF transmission. Equally important, an IRS creates a valuable resource in wireless communication, i.e., control over channel realizations from IRS relays to the receiver(s). In this work, we investigated the impact of this resource on improving secure communication rates between a transmitter (base station) and a receiver (end user). Specifically, we characterized the scaling behavior of the secure transmission rate for a multi-antenna wiretap channel aided with an IRS. Compared to our previous work where active user cooperation enables/improves secure communication rates, here secure communication is enabled/improved by utilizing passive terminals deployed at a very low cost.
-
-
-
-
-
-
1.2. Adversarial designed attacks [Nafea, Yener, 2015] [Nafea, Yener, 2017] [Nafea, Yener, 2017] [Nafea, Yener, 2017] [Nafea, Yener, 2019]
- The wiretap II model, introduced in 1984, is a well received adversary model due to its elegance in featuring a strategic wiretapper (adversary); the adversary chooses the positions of symbols it taps into (noiselessly overhears), with a fixed budget on the fraction of tapped symbols. The model has various applications besides wireless communications, including secure distributed storage, network coding, and private information retrieval. The model remained linked to the assumption of a noiseless main (legitimate) channel for three decades. This work is the first to relax this assumption, by introducing a noisy main channel to the model. Further, we introduced a generalized wiretap model which subsumes both the classical wiretap and wiretap II models as extreme cases; the adversary chooses a subset of transmitted symbols to tap into and observes the remainder through a noisy channel. We derived the strong secrecy capacity (i.e., maximum reliable and strongly secure transmission rate) of the model and showed it is identical to the secrecy capacity when the tapped positions are randomly chosen. Our analysis showed that stochastic wiretap encoding is robust against such a strategic adversary; it provides a super-exponential convergence rate for the strong security measure, which dominates the exponentially many possible strategies for the adversary. Finally, we investigated several multi-terminal extensions including multiple-access, broadcast, and interference channels.
-
-
-
-
-
1.3. Adversarial designed attacks in cache-aided communication systems [Nafea, Yener, 2021]
- This project introduced the notion of cache tapping into information-theoretic models of coded caching: The adversary taps into a subset of symbols of its choice either from cache placement, delivery, or both phases. The legitimate parties know neither the relative fractions of tapped symbols in both phases, nor their positions. We derived the strong secrecy capacity– maximum achievable file size while keeping the whole library secure– for the instance of two users and two library files. We derived lower and upper bounds on the secure file rate, for multiple library files. To achieve capacity, we designed a channel code which integrates stochastic encoding, security embedding codes, one-time pad keys, and coded caching techniques. Our results establish provable strong security against a powerful adversary which optimizes its designed attack over both phases of a cache-aided communication system.
-
-
-
-
-
1.4. Multi-terminal networks with untrusted nodes [Zewail, Nafea, et al., 2014]
- We investigated information-theoretic security guarantees in complex network topologies; we studied the impact of cooperation with an untrusted relay in a multi-source multi-destination network with no direct links. The relay follows the transmission protocol, but is not trusted with and to be kept ignorant of the communicated messages. We derived inner and outer bounds on the secrecy capacity.
-
-
-
-
-
1.5. Future directions: The case of active adversaries
- In our research on designed adversarial attacks, we addressed a strategic adversary with large yet finite strategy space: The adversary chooses αn out of n symbol positions to tap into. We showed the existence of universal transmission schemes that are optimal regardless the actions taken by the adversary. Existence of such schemes may cease to hold when the adversary carries out active attacks such as jamming (erasure) or impersonation; here, the strategy space for the adversary can be significantly larger than a passive wiretapper adversary. Investigating secure communication against such adversaries, and whether feedback about the adversary’s actions is needed to achieve non-zero secure rate, would provide a holistic view to complement our work with non-active adversaries
-
-
-
-
2. Influence Propagation in Social Sensor Networks [Guler et.al.]
-
We introduced a propagation mode in a social sensor network where relationships are modeled by positive/negative signs. The system designer is aware of the underlying social graph through observations of socially aware sensors. We investigated minimizing end-to-end propagation cost of influencing a target person in favor of an idea. We also studied the propagation model when minimizing the number of negatively influenced persons. We demonstrated our results using an artificially created network and the Epinions signed network topology. Our results show that network propagation cost can be significantly reduced compared to naive myopic schemes.
-
-